all snippets of code are shortened for brevity
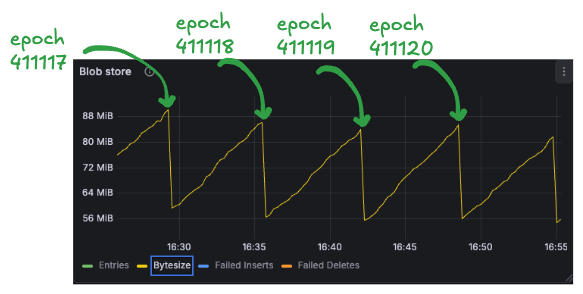
i was skimming through Reth’s metrics and I found this interesting sawtooth wave pattern in the transaction pool’s metrics

 so i decided to take a deeper look at it and figure out how blobs are maintained in Reth terms
so i decided to take a deeper look at it and figure out how blobs are maintained in Reth terms
maintain.rs
the main tx-pool maintainer.rs function maintain_transaction_pool is located here https://github.com/paradigmxyz/reth/blob/main/crates/transaction-pool/src/maintain.rs#L123
there’s a lot going on here but inside the loop is where the most important part (for us) resides:
// check if we have a new finalized block
if let Some(finalized) =
last_finalized_block.update(client.finalized_block_number().ok().flatten()) &&
let BlobStoreUpdates::Finalized(blobs) =
blob_store_tracker.on_finalized_block(finalized)
{
metrics.inc_deleted_tracked_blobs(blobs.len());
// remove all finalized blobs from the blob store
pool.delete_blobs(blobs);
// and also do periodic cleanup
let pool = pool.clone();
task_spawner.spawn_blocking(Box::pin(async move {
debug!(target: "txpool", finalized_block = %finalized, "cleaning up blob store");
pool.cleanup_blobs();
}));
}a block is considered finalized if:
- it’s higher than the last one we saw which is stored at
self.last_finalized_block - there are blob transactions in the now-finalized blocks that need to be cleaned up
let’s break it down:
condition 1: did finalization advance?
last_finalized_block.update(client.finalized_block_number().ok().flatten())this asks the consensus layer “what’s the latest finalized block?” and compares it to the last one we saw. the update function returns Some(block_number) only if finalization actually moved forward; otherwise it returns None and we skip the whole block.
condition 2: are there blobs to delete?
blob_store_tracker.on_finalized_block(finalized)this is where it gets interesting. the tracker keeps a BTreeMap<BlockNumber, Vec<B256>> that maps block numbers to the blob transaction hashes that were mined in that block.
pub fn on_finalized_block(&mut self, finalized_block: BlockNumber) -> BlobStoreUpdates {
let mut finalized = Vec::new();
while let Some(entry) = self.blob_txs_in_blocks.first_entry() {
if *entry.key() <= finalized_block {
finalized.extend(entry.remove_entry().1);
} else {
break
}
}
// ...
}here’s the logic:
first_entry()grabs the first block number in the map (should be the lowest/oldest block in the map)- if that block number ≤ the new finalized block, those blobs must be finalized → remove them from the map and collect their hashes
- keep going until we hit a block that’s still not finalized (which should be the one we are working with now)
- return all the collected hashes (
finalized) so they can be deleted from the blob store
so the tracker always holds blobs that are not yet finalized. once finalization catches up, they get pruned. that’s why we see the sawtooth pattern; blobs accumulate as new blob transactions get mined (~3-6 per block), then drop when an epoch finalizes.
the actual deletion
once we have the list of finalized blob tx hashes, two things happen:
pool.delete_blobs(blobs); // calls self.blob_store.delete_all()
// and periodically
pool.cleanup_blobs(); // calls self.blob_store.cleanup()there are two implementations for depending on our config:
- in-memory store (
InMemoryBlobStore) https://github.com/paradigmxyz/reth/blob/main/crates/transaction-pool/src/blobstore/mem.rs
delete_all() grabs the write lock, removes each tx hash from the hashmap, updates the size tracker
fn delete_all(&self, txs: Vec<B256>) -> Result<(), BlobStoreError> {
let mut store = self.inner.store.write();
for tx in txs {
total_sub += remove_size(&mut store, &tx);
}
self.inner.size_tracker.sub_size(total_sub);
Ok(())
}cleanup() just returns the default values for the blobstore
fn cleanup(&self) -> BlobStoreCleanupStat {
BlobStoreCleanupStat::default()
}- disk store (
DiskFileBlobStore) https://github.com/paradigmxyz/reth/blob/main/crates/transaction-pool/src/blobstore/disk.rs here, deletion is deferred. the tx hashes are just added to atxs_to_deletequeue.
fn delete_all(&self, txs: Vec<B256>) -> Result<(), BlobStoreError> {
let txs = self.inner.retain_existing(txs)?;
self.inner.txs_to_delete.write().extend(txs);
Ok(())
}the actual file deletion happens in cleanup():
fn cleanup(&self) -> BlobStoreCleanupStat {
let txs_to_delete = std::mem::take(&mut *self.inner.txs_to_delete.write());
for tx in txs_to_delete {
let path = self.inner.blob_disk_file(tx);
match fs::remove_file(&path) {
Ok(_) => stat.delete_succeed += 1,
Err(e) => stat.delete_failed += 1,
};
}
}this is why the maintain loop spawns a blocking task for cleanup, since we don’t want to stall the main maintenance loop
task_spawner.spawn_blocking(Box::pin(async move {
debug!(target: "txpool", finalized_block = %finalized, "cleaning up blob store");
pool.cleanup_blobs();
}));the actual disk cleanup runs in a separate thread pool while the main loop continues processing new blocks.
this deferred cleanup pattern is why we might see the “Failed Deletes” metric tick up occasionally; if a file fails to be deleted, the cleanup just logs it and moves on.
correlating with mainnet data
i grabbed some data from my full nightly node running at v1.9.3 and cross-referenced it with epoch timestamps from ethpandaops
| epoch | start time (GMT) | entries before | entries after | blobs deleted | blobs/block | MiB before | MiB after | MiB freed | avg sidecar size |
|---|---|---|---|---|---|---|---|---|---|
| 411117 | 16:29:11 | 350 | 233 | ~117 | 3.7 | 90.1 | 59.4 | 30.7 | ~262 KiB |
| 411118 | 16:35:35 | 354 | 248 | ~106 | 3.3 | 86.1 | 56.4 | 29.7 | ~280 KiB |
| 411119 | 16:41:59 | 374 | 245 | ~129 | 4.0 | 84.1 | 55.4 | 28.7 | ~222 KiB |
| 411120 | 16:48:23 | 377 | 240 | ~137 | 4.3 | 85.3 | 56.0 | 29.3 | ~214 KiB |
the drops align with epoch boundaries (~6.4 minutes apart). each finalization prunes around 100-130 blob sidecars, freeing up ~30 MiB of memory.
the avg sidecar size being above 128Kb should be normal due to memory/runtime overheads.
we’re seeing about 3-4 blob transactions per block on average, with the current max of 6 blobs per block. with PeerDAS + BPO forks coming in Fusaka (epoch 411392!) we’ll be able to increase the max blobs per block from 6 to +128 overtime.